
跨摄像头行人再识别
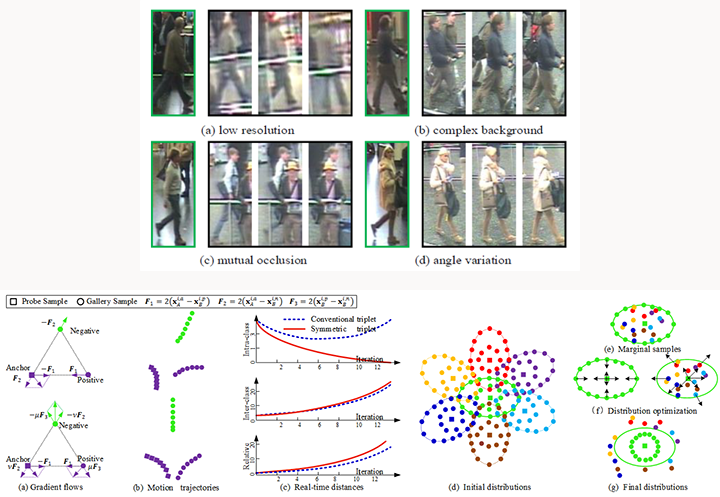 | Point to Set Similarity Based Deep Feature Learning for Person Re-identificationSanping Zhou, Jinjun Wang, Jiayun Wang, Yihong Gong, Nanning Zheng CVPR, 2017 Person re-identification (Re-ID) remains a challenging problem due to significant appearance changes caused by variations in view angle, background clutter, illumination condition and mutual occlusion. To address these issues, conventional methods usually focus on proposing robust feature representation or learning metric transformation based on pairwise similarity, using Fisher-type criterion. The recent development in deep learning based approaches address the two processes in a joint fashion and have achieved promising progress. One of the key issues for deep learning based person Re-ID is the selection of proper similarity comparison criteria, and the performance of learned features using existing criterion based on pairwise similarity is still limited, because only P2P distances are mostly considered. In this paper, we present a novel person Re-ID method based on P2S similarity comparison. The P2S metric can jointly minimize the intra-class distance and maximize the inter-class distance, while back-propagating the gradient to optimize parameters of the deep model. By utilizing our proposed P2S metric, the learned deep model can effectively distinguish different persons by learning discriminative and stable feature representations. Comprehensive experimental evaluations on 3DPeS, CUHK01, PRID2011 and Market1501 datasets demonstrate the advantages of our method over the state-of-the-art approaches. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
跨镜头多人脸跟踪
 | Tracking Persons-of-Interest via Adaptive Discriminative FeaturesShun Zhang, Yihong Gong, Jia-Bin Huang, Jongwoo Lim, Jinjun Wang, Narendra Ahuja and Ming-Hsuan Yang ECCV, 2016 Multi-face tracking in unconstrained videos is a challenging problem as faces of one person often appear drastically different in multiple shots due to significant variations in scale, pose, expression, illumination, and make-up. Low level features used in existing multi-target tracking methods are not effective for identifying faces with such large appearance variations. In this paper, we tackle this problem by learning discriminative, video-specific face features using convolutional neural networks (CNNs). Unlike existing CNN-based approaches that are only trained on large-scale face image datasets offline, we further adapt the pre-trained face CNN to specific videos using automatically discovered training samples from tracklets. Our network directly optimizes the embedding space so that the Euclidean distances correspond to a measure of semantic face similarity. This is technically realized by minimizing an improved triplet loss function. With the learned discriminative features, we apply the Hungarian algorithm to link tracklets within each shot and the hierarchical clustering algorithm to link tracklets across multiple shots to form final trajectories. We extensively evaluate the proposed algorithm on a set of TV sitcoms and music videos and demonstrate significant performance improvement over existing techniques. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
深度特征学习
 | Improving DCNN Performance with Sparse Category-Selective Objective FunctionShizhou Zhang, Yihong Gong, JinjunWang IJCAI, 2016 we choose to learn useful cues fromobject recognition mechanisms of the human visualcortex, and propose a DCNN performance improvementmethod without the need for increasingthe network complexity. Inspired by the categoryselectiveproperty of the neuron population in theIT layer of the human visual cortex, we enforcethe neuron responses at the top DCNN layer to becategory selective. To achieve this, we proposethe Sparse Category-Selective Objective Function(SCSOF) to modulate the neuron outputs of thetop DCNN layer. The proposed method is genericand can be applied to any DCNN models. As experimentalresults show, when applying the proposedmethod to the “Quick” model and NINmodels, image classification performances are remarkablyimproved on four widely used benchmarkdatasets: CIFAR-10, CIFAR-100, MNISTand SVHN, which demonstrate the effectiveness ofthe presented method. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
多目标跟踪
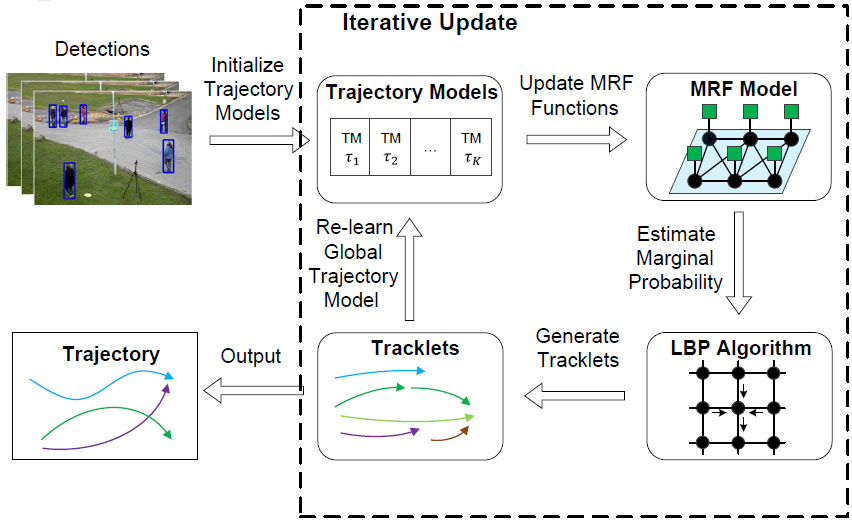 | Multi-target tracking by learnin glocal-to-global trajectory modelsShun Zhang, Jinjun Wang, Zelun Wang, Yihong Gong and Yuehu Liu Pattern Recognition, 2014 The multi-target tracking problem is challenging when there exist occlusions, tracking failures of the detector and severe interferences between detections. In this paper, we propose a novel detection based tracking method that links detections into tracklets and further forms long trajectories. Unlike many previous hierarchical frameworks which split the data association into two separate optimization problems (linking detections locally and linking tracklets globally), we introduce a unified algorithm that can automatically relearn the trajectory models from the local and global information for finding the joint optimal assignment. In each temporal window, the trajectory models are initialized by the local information to link those easy-to-connect detections into a set of tracklets. Then the trajectory models are updated by the reliable tracklets and reused to link separated tracklets into long trajectories. We iteratively update the trajectory models by more information from more frames until the result converges. The iterative process gradually improves the accuracy of the trajectory models, which in turn improves the target ID inferences for all detections by the MRF model. Experiment results revealed that our proposed method achieved state-of-the-art multi-target tracking performance. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
图像特征表达
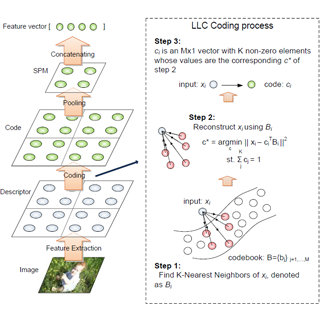 | Locality-constrained Linear Coding for Image ClassificationJinjun Wang, Jianchao Yang, Kai Yu, Fengjun Lv, Thomas Huang and Yihong Gong Proc. of IEEE Conference on Computer Vision and Pattern Recognition 2010 The traditional SPM approach based on bag-of-features (BoF) must use nonlinear classifiers to achieve good image classification performance. This paper presents a simple but effective coding scheme called Locality-constrained Linear Coding (LLC) in place of the VQ coding in traditional SPM. LLC utilizes the locality constraints to project each descriptor into its local-coordinate system, and the projected coordinates are integrated by max pooling to generate the final representation. With linear classifier, the proposed approach performs remarkably better than the traditional nonlinear SPM, achieving state-of-the-art performance on several benchmarks. Compared with the sparse coding strategy [22], the objective function used by LCC has an analytical solution, bearing much lower computational complexity of O(M + M) with M the size of codebook. In addition, the paper proposes an approximated LCC method by first performing a K-nearest-neighbor search and then solving a constrained least square fitting problem, further reducing the computational complexity to O(M+K). Hence even with very large codebooks, our system can still process multiple frames per second. This efficiency significantly adds to the practical values of LLC for real applications. [pdf] | |
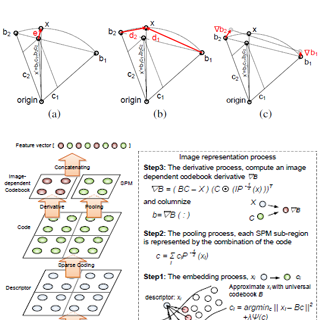 | Discovering Image Semantics in Codebook Derivative SpaceJinjun Wang and Yihong Gong IEEE Trans. on Multimedia,vol.14, issue.4,pp 986-994, August 2012 The sparse coding based approaches for image recognition have recently shown improved performance than traditional bag-of-features technique. Due to high dimensionality of the image descriptor space, existing systems usually require very large codebook size to minimize coding error in order to get satisfactory accuracy. While most research efforts try to address the problem by constructing a relatively smaller codebook with stronger discriminative power, in this paper, we introduce an alternative solution by enhancing the quality of coding. Particularly, we apply the idea similar to Fisher kernel to the coding framework, where we use the image-dependent codebook derivative to represent the image. The proposed idea is generic across multiple coding criteria, and in this paper, it is applied to enhance the Locality-constraint Linear Coding (LLC). Experiments show that, the extracted new feature, called “LLC+”, achieved significantly improved accuracy on several challenging datasets even with a small codebook of 1/20 the reported size used by LLC. This obviously adds to LLC+ the modeling accuracy, processing speed and codebook training advantages. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
图像与视频超分辨率
 | Resolution-Invariant Image Representation and Its ApplicationsJinjun Wang, Shenghuo Zhu, Yihong Gong Proc. of IEEE Conference on Computer Vision and Pattern Recognition 2009 We present a Resolution-Invariant Image Representation (RIIR) framework in this paper. The RIIR framework includes the methods of building a set of multi-resolution bases from training images, estimating the optimal sparse resolution-invariant representation of any image, and reconstructing the missing patches of any resolution level. As the proposed RIIR framework has many potential resolution enhancement applications, we discuss three novel image magnification applications in this paper. In the first application, we apply the RIIR framework to perform Multi-Scale Image Magnification where we also introduced a training strategy to built a compact RIIR set. In the second application, the RIIR framework is extended to conduct Continuous Image Scaling where a new base at any resolution level can be generated using existing RIIR set on the fly. In the third application, we further apply the RIIR framework onto Content-Base Automatic Zooming applications. The experimental results show that in all these applications, our RIIR based method outperforms existing methods in various aspects. [pdf] | |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
人物动作识别
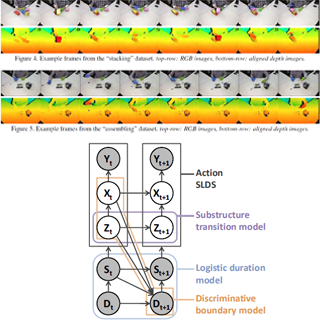 | Substructure and Boundary Modeling for Continuous Action RecognitionZhaowen Wang, Jinjun Wang*, Jing Xiao, Kai-Hsiang Lin and Thomas Huang Proc. of IEEE Conference on Computer Vision and Pattern Recognition 2012 This work introduces a probabilistic graphical model for continuous action recognition with two novel components: substructure transition model and discriminative boundary model. The first component encodes the sparse and global temporal transition prior between action primitives in state-space model to handle the large spatialtemporal variations within an action class. The second component enforces the action duration constraint in a discriminative way to locate the transition boundaries between actions more accurately. The two components are integrated into a unified graphical structure to enable effective training and inference. Our comprehensive experimental results on both public and in-house datasets show that, with the capability to incorporate additional information that had not been explicitly or efficiently modeled by previous methods, our proposed algorithm achieved significantly improved performance for continuous action recognition. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
基于内容的视频检索与自动编辑
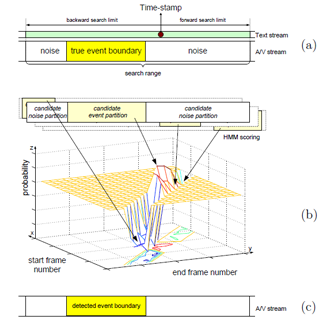
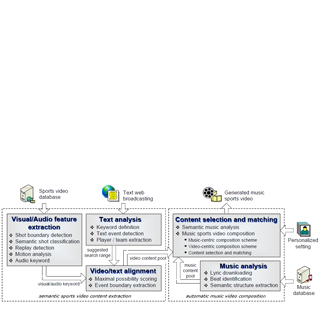 | A Novel Framework for Semantic Annotation and Personalized Retrieval of Sports VideoChangsheng Xu, Jinjun Wang, Hanqing Lu and Yifan Zhang IEEE Trans. on Multimedia; vol. 10, issue. 3, pp 421-436, 2008 In this paper, we propose a novel automatic approach for personalized music sports video generation. Two research challenges are addressed, specifically the semantic sports video content extraction and the automatic music video composition. For the first challenge, we propose to use multimodal (audio, video, and text) feature analysis and alignment to detect the semantics of events in broadcast sports video. For the second challenge, we introduce the video-centric and music-centric music video composition schemes and proposed a dynamic-programming based algorithm to perform fully or semi-automatic generation of personalized music sports video. The experimental results and user evaluations are promising and show that our system’s generated music sports video is comparable to professionally generated ones. Our proposed system greatly facilitates the music sports video editing task for both professionals and amateurs. [pdf] | |
 | Generation of Personalized Music Sports Video Using Multimodal CuesJinjun Wang, Engsiong Chng, Changsheng Xu, Hanqinq Lu and Qi Tian IEEE Trans. on Multimedia,vol.9, issue.3, pp 576-588, April 2007 The sparse coding based approaches for image recognition have recently shown improved performance than traditional bag-of-features technique. Due to high dimensionality of the image descriptor space, existing systems usually require very large codebook size to minimize coding error in order to get satisfactory accuracy. While most research efforts try to address the problem by constructing a relatively smaller codebook with stronger discriminative power, in this paper, we introduce an alternative solution by enhancing the quality of coding. Particularly, we apply the idea similar to Fisher kernel to the coding framework, where we use the image-dependent codebook derivative to represent the image. The proposed idea is generic across multiple coding criteria, and in this paper, it is applied to enhance the Locality-constraint Linear Coding (LLC). Experiments show that, the extracted new feature, called “LLC+”, achieved significantly improved accuracy on several challenging datasets even with a small codebook of 1/20 the reported size used by LLC. This obviously adds to LLC+ the modeling accuracy, processing speed and codebook training advantages. [pdf] |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
智能汽车
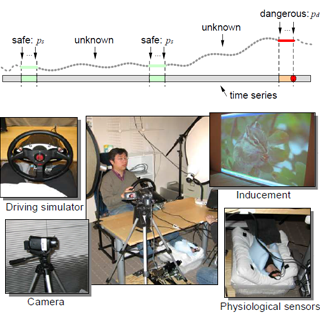 | Driving Safety Monitoring Using Semisupervised Learning on Time Series DataJinjun Wang, Shenghuo Zhu and Yihong Gong IEEE Trans. on Intelligent Transportation Sys., vol. 11, issue 3, pp 728-737, Sept. 2010 This work introduces a dangerous-driving warning system that uses statistical modeling to predict driving risks. The major challenge of the research is how to discover the safe/dangerous driving patterns from a sparsely labeled training data set. This paper proposes a semisupervised learning method to utilize both the labeled and the unlabeled data, as well as their interdependence to build a proper danger-level function. In addition, the learned function adopts a continuous parametric form, which is more suitable in modeling the continuous safe/dangerous-driving state transitions in a practical dangerousdriving warning system. Our comprehensive experimental evaluations reveal that, in comparison with driving danger-level estimation using classification-based methods, such as the hidden Markov model (HMM) or the conditional random field algorithm, the proposed method requires less training time and achieved higher prediction accuracy. Index Terms—Driving safety monitoring, functional safety, semisupervised learning. [pdf] |
 (创新港)
(创新港)


