
开放动态场景的多形态自主移动智能体三维视觉感知大模型研究及应用
在人工智能时代,无人车、移动机器人、无人机、AGV等自主移动智能体在各行各业有着广泛的应用前景。自主智能体通过集成视觉相机、激光雷达、红外等多模态视觉传感器搭建3D视觉系统,以获取开放动态场景的3D数据和感知3D场景,包括深度图计算、3D目标检测、3D重建、SLAM定位与建图,以及多智能体协同感知等。然而,受视觉传感器技术局限性和开放动态环境复杂性的影响,目前自主智能体视觉系统的性能远远无法满足需求。
通用人工智能(AGI),也叫强人工智能,目标是使智能体具备像人一样理解或学习复杂任务的能力,一般需要具备功能多样性(多任务)和环境适应性(强泛化)两方面属性。ChatGPT的问世成为通用人工智能或强人工智能发展的里程碑,也为自主智能体提供了语言大模型解决方案。然而,自主智能体的环境感知大模型研究仍是一个开放问题,本课题组长期致力于研究面向多形态自主智能体的通用三维环境感知模型研究,为动态开放场景的机器人适应环境、人机交互、自主操作、学习决策提供视觉技术支撑。
课题组近年来围绕自主智能体的多模态3D视觉感知问题开展相关基础理论、算法模型研究,承担了国家自然基金、国家重点研发计划、广东省重点研发计划、JKW课题等项目,在IEEE Trans. Pattern Anal. Mach. Intell., IEEE Trans. Image Process., IEEE Trans. Multimedia, IEEE Trans. Broadcast., Pattern Recognition等权威国际期刊和会议上发表数十篇论文,并把研究成果应用于机器人、移动小车、无人驾驶、无人机等自主移动智能体中,推动自主移动智能体在各类工业场景中落地。
部分研究结果展示如下:
1、开放场景的自主智能体多模态稀疏点云补全


2、交通场景的自主智能体多模态稀疏点云补全

3、未知室内场景的单目绝对深度预测与三维场景优化
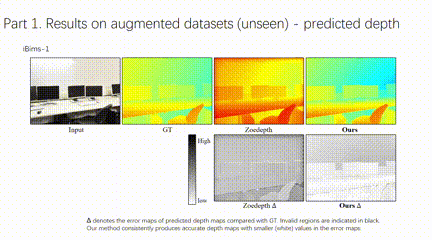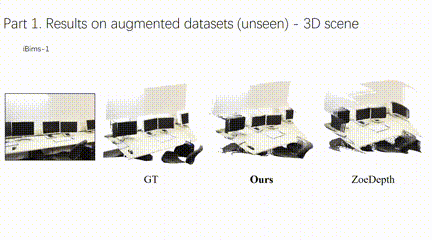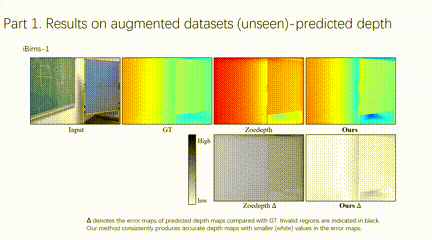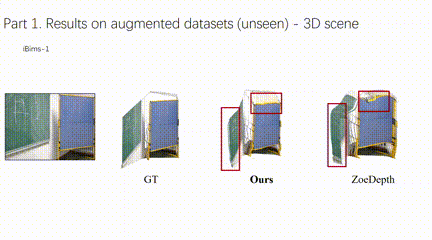
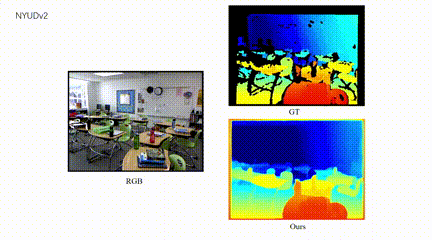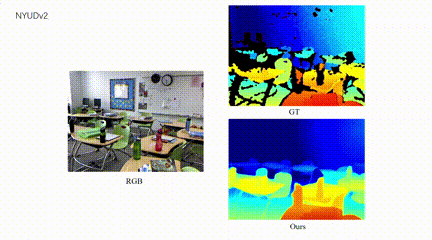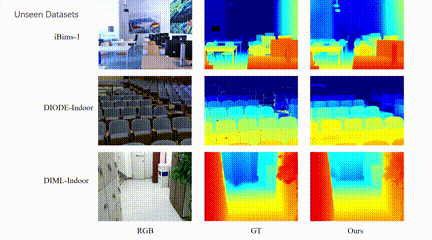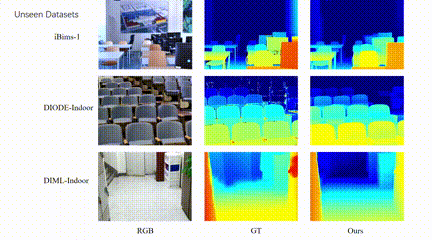
4、自主智能体单目深度图结构增强

5、室内场景的自主智能体未知3D目标检测

6、室内场景的多智能体协作与障碍物感知

7、结构化场景的自主智能体任务分配

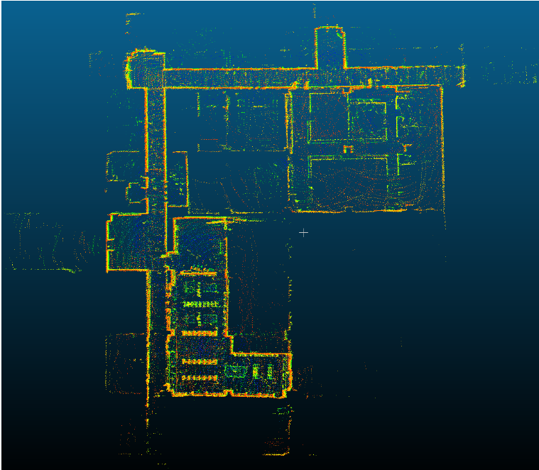
8、室内场景的自主智能体建图与定位
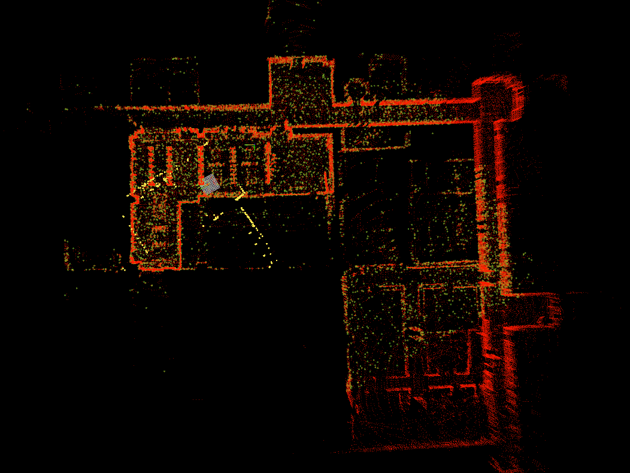
9、交通场景的多视角障碍物感知与定位

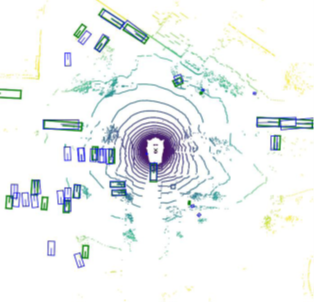

10、多智能体协同路经规划

 (创新港)
(创新港)


