
Personal profile
暂未填写

下载: https://pan.baidu.com/s/1d62pjaN71NzqNMcS0rzpjA?pwd=1234
软件使用说明
听写和跟读是学习外语的重要方法。 总体而言, 听写有三种方式: 分句听写、 有笔记意群听写、 无笔记精听再默写或复述。 至于这些方法的优劣请参阅知乎网专业人士关于“句子听写”、“有笔记式精听” 、 “无笔记式精听” 的相关讨论。 笔者长期学习外语, 做过大量听写训练。根据自身的经验, 笔者认为分句听写类似于借助句子背单词(包括记忆声音和拼写) , 无笔记精听对于实际听力水平的提高最有帮助(听结构、 抓意群) 。 如果你想尽快提高英语水平, 特别是听力水平, 一定要选择适合你的练习方法以及学习材料。 否则, 可能长期原地踏步或进步缓慢。
Dictation 软件是笔者编写的一个英语听写、 跟读软件。 该软件实现了分句听写、 全文听写两种学习方式, 还具有录音以及回放功能, 适合在个人电脑上使用。
有些听力的 mp3 音频配有同步歌词文件, 这些文件是以.lrc 为后缀的文本文件。 除后缀外,歌词文件名称一般与音频文件名一致。 歌词文件将听力原文分成许多段落, 并标记了每一段的起始时间和内容, 用于在手机或 mp3 播放器上播放音频时同步显示歌词。
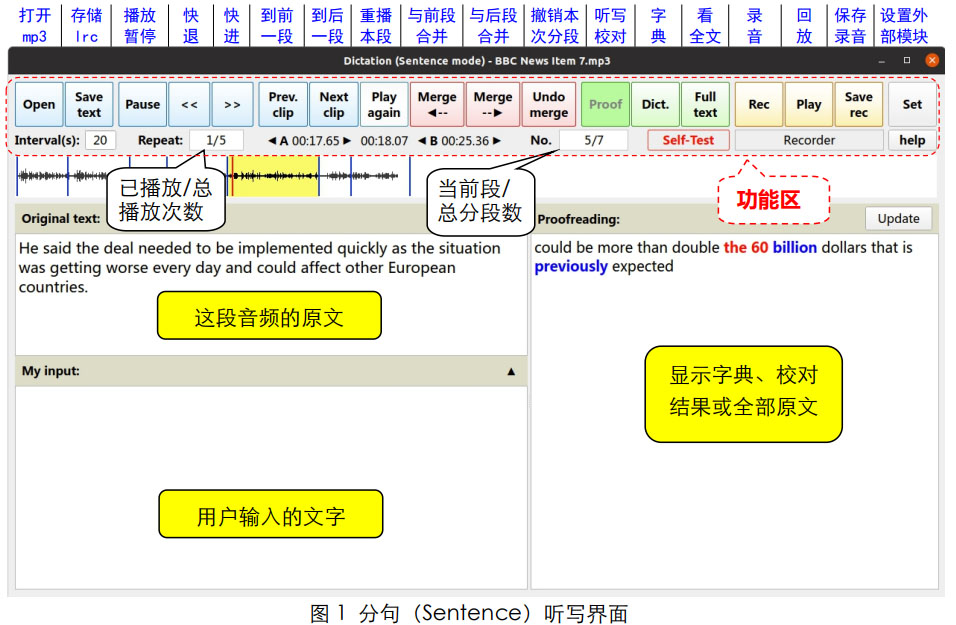
如果一个 mp3 音频的 lrc 文件包含多个时间标签, 使用 Open 按钮打开此 mp3 文件, 软件将进入分句听写模式, 界面如图 1 所示。界面各按钮功能简介
(1) Open: 打开 mp3 音频。 该音频目录下有同名的 lrc 文件或原文的 txt 文件。 若无 lrc或 txt 文件时, 音频无法使用。 若有 lrc 文件, 软件进入分句听写模式; 若有 txt 文件,软件进入全文听写模式。
(2) Save text: 若音频分段有更改, 或者某分段的文本被修改, 此功能可存储新的 lrc 或txt 文件。 在分句听写模式下, 只能修改 lrc 文件; 在全文听写模式下, 只能修改 txt文件。
(3) Play/Pause: 播放/暂停播放, 仅播放当前音频段。 将自动播放的总次数、 已播放次数见 repeat 区域, 其中播放总次数可调整( ) 。 播放间隔时间见 Interval(s)区域, 该数值也可调整( ) 。
(4) <<、 >>: 快进、 快退范围被限制到当前音频分段内。
(5) Prev. clip、 Next clip: 跳转到前一分段、 跳转到后一分段。 跳转时, 下方 Original text也随之变化; 在第二行 No.区域输入某个段号( ) , 再点击 No.按钮, 可以直接跳转到某一个分段。
(6) Play again: 立即重新播放当前分段。 不受 repeat 播放总次数限制;
(7) ◄--Merge、 Merge--►、 Undo Merge: 合并当前段与前一段、 合并当前段与后一段、撤销本次分段。
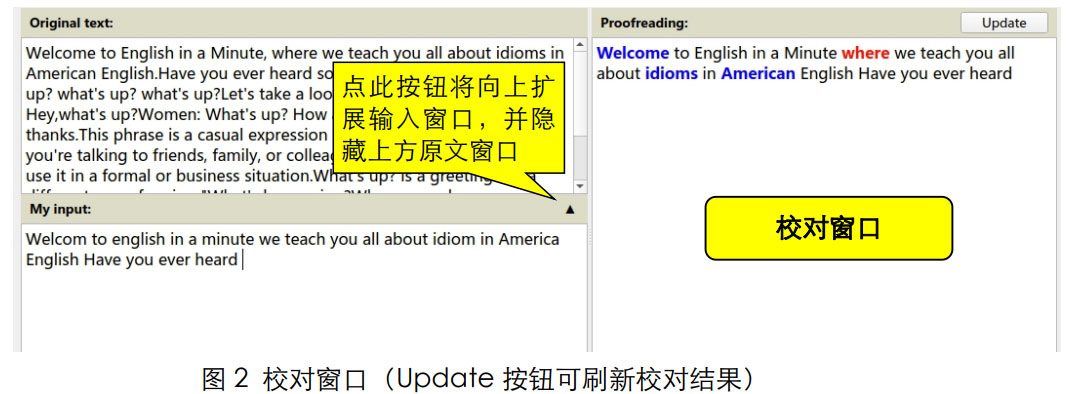
(8) Proof: 点此按钮显示图 2 的文本校对窗口。 校对窗口中显示原文文本, 黑色代表拼写正确的单词, 蓝色代表没有完全拼写正确的单词, 红色代表遗漏的或完全写错的单词。
本功能可以设定交给外部程序模块处理。
(9) Dict. : 英汉字典(美国传统字典) 。 可以划词查询、 输入单词查询(见图 3) ;

(10)Full text: 显示全部原文, 如有中文解释也将显示;
(11)Rec/Stop: 点击 Rec 按钮, 开始录音; 再次点击此按钮, 录音结束。
(12)Play/Stop: 点击 Play 按钮, 开始播放录音; 再次点击此按钮, 回放结束。
(13)Save: 此功能可保存录音为 mp3 文件。
(14) Set: 点此按钮呼出图 6 所示对话框, 此对话框可以设定实现音频自动分段和文本对比的外部模块。 (注: 笔者将这一功能用于大学的计算机课程教学, 请学生用 python 语言或其他语言实现这两个模块。 )
如果 mp3 音频没有.lrc 文件, 那么使用原文可以进入全文听写模式。 这需要将音频的原文另存为.txt 文本文件, 除后缀外 txt 文件应和 mp3 文件同名, 建议存储为 utf-8 编码格式。 如果既没有.lrc 文件, 也没有.txt 文件, 本软件不会打开音频文件。
打开一个 mp3 音频时, 如果发现只有.lrc 文件, 软件将直接进入分句听写界面; 如果发现只有.txt 文件, 软件将直接进入全文听写界面; 如果同时发现.lrc 文件和.txt 文件, 将弹出对话框, 由用户选择进入哪一种学习模式。
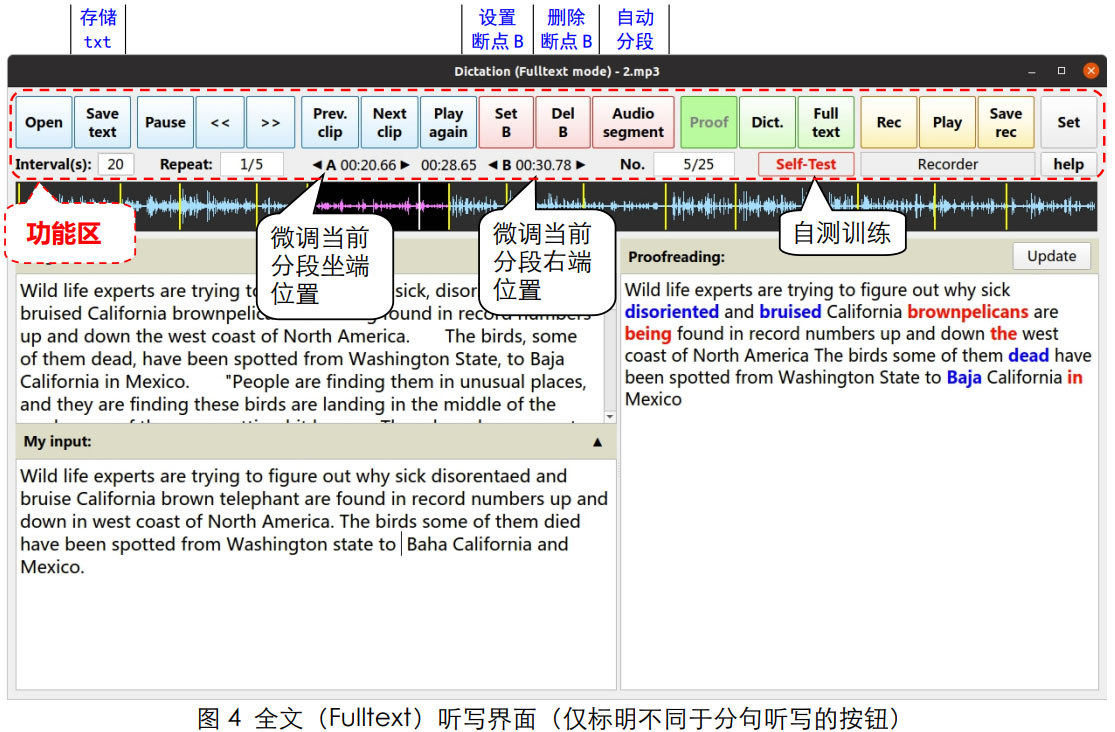
在全文学习模式中, 与分句听写的功能主要是以下三项:
(1) Set B: 在音频当前播放位置加入断点。 注意, 断点位置与原有断点距离太近(1s 左右) 将不增加断点。
(2) Del B: 删除当前音频分段结束位置的断点。 注意, 整个音频结束的最后一个断点不能删除。
(3) Audio segment: 自动分割音频, 大致 8 秒左右一段。 主要根据静音位置分段, 附加句子时长的考量。 本功能可以设定交给外部程序模块处理
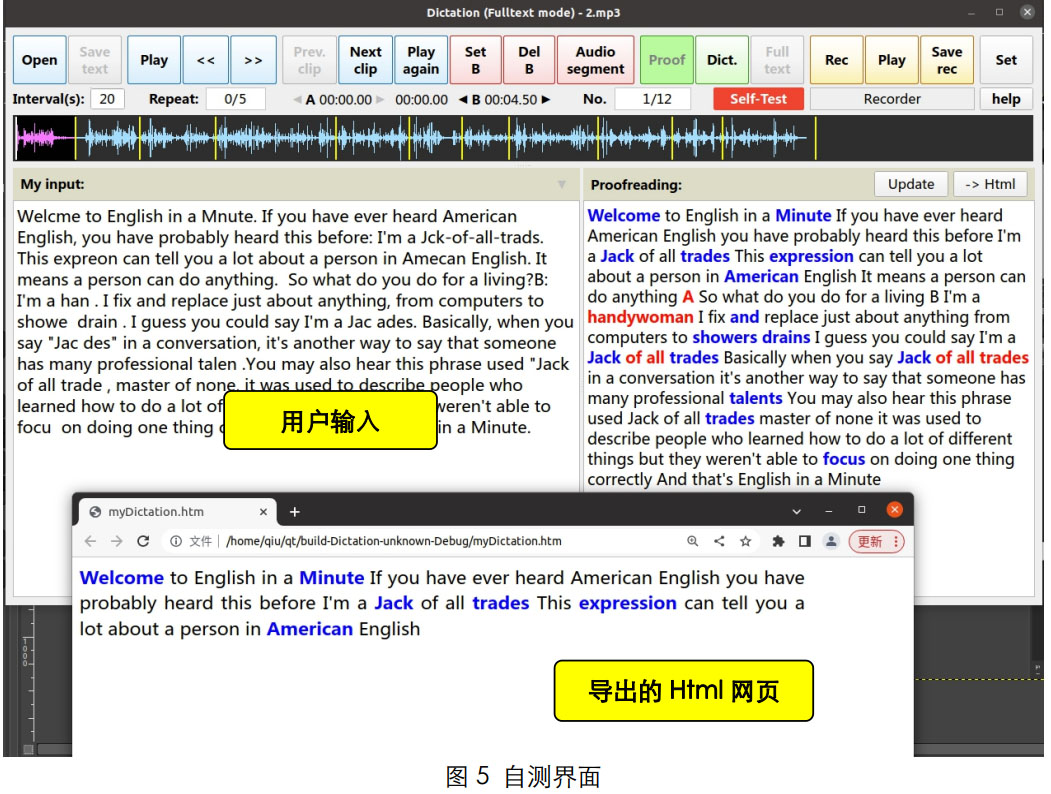
在全文听写模式下, 分段信息也会保存。 当再次保存.txt 文件时, 原文将放在文档头部; 分段信息会分成多行放在原文信息后面, 每行一个时间标签。
分句听写与全文听写主要的不同是:
分句听写将全文分成了若干段落, 每次跳转到其他段落, 原文会跟着变化。 校对的内容仅仅是这一段文字。
全文听写虽然也可以分段, 但是整个听写原文是放在一起的, 不会随句子的跳转而变化。 校对也是全文校对。 软件默认的算法将比对用户已经写出的内容, 用户没有写出的内容将不会比对。
关于软件的音频自动分段算法和文本对比算法, 我个人认为并不完美。 如果有人有更好的算法, 欢迎交流讨论。
以下为表格为本软件的快捷操作汇总。 注意, 有些操作需要输入光标(焦点) 位于输入窗口或原文窗口时才起作用。 若发现某个快捷键失效, 则点击输入窗口后就可使用。 如果利用鼠标进行分段, 在波形图上双击鼠标左键时, 需要距离其他分段点 1 秒以上(16 像素) 才能添加分段点; 在波形图上双击鼠标右键时, 需要靠近被删除的分段点。
| 操 作 | 功 能 | 操 作 | 功 能 |
|---|---|---|---|
| ESC | Play/Pause | F9 | Rec/Stop |
| F1 | << | F10 | Play/Stop Rec |
| F2 | >> | F11 | Proofreading |
| F3 | Previous Clip | Ctrl + PageUp | ◄-- Merge |
| F4 | Next Clip | Ctrl + PageDown | Merge --► |
| F5 | Play again | Alt + → | A ► |
| F6 或 在波形图上双击鼠标左键 | Set B | Alt + ← | ◄ A |
| Alt + ↑ | B ► | ||
| Alt + ↓ | ◄ B | ||
| F7 或 在波形图上双击鼠标左键 | Del B | Ctrl + O | Open |
| Ctel + S | Save |
版权所有:西安交通大学 陕ICP备05001571号
