
1. 基于深度学习算法的可见光海面目标检测跟踪系统
项目背景
近年来无人艇技术发展迅速。通过搭载高清摄像机或光电跟踪仪等设备和视觉检测技术,无人艇可以在危险海域对目标进行侦查、监视或跟踪, 逐渐成为保证海面安全不可或缺的技术。但是水面存在目标难以采样,目标形变、光照变化、尺度变化、目标遮挡、摄像头抖动等多种状况,这些问题增加了海面目标的视觉检测跟踪的难度,可能导致虚警、漏检或跟踪失败。本项目针对上述问题,基于yolov5和deepsort算法,设计了针对可见光海面目标检测系统。该系统由海面目标离线训练平台和海面目标在线检测跟踪平台组成,可对无人艇采集的可见光视频中实现海面目标的检测、识别与跟踪,具有较高的稳定性和实时性。
实施方案
总体系统搭建:
基于深度学习算法的可见光海面目标检测跟踪系统主要分为两部分:一部分是位于数据处理伺服器的舰船图像离线训练平台,这一部分主要负责存储无人艇采集的各类可见光海面目标视频序列,同时负责离线舰船目标检测模型的离线训练;另一部分是位于指挥所、舰船或其他武器装备终端上的海面目标在线识别平台,根据舰船图像离线训练平台得到的海面目标检测的训练模型对无人艇所搭载的高清摄像头或光电跟踪仪回传的视频序列当中的海面目标进行检测、识别和跟踪。
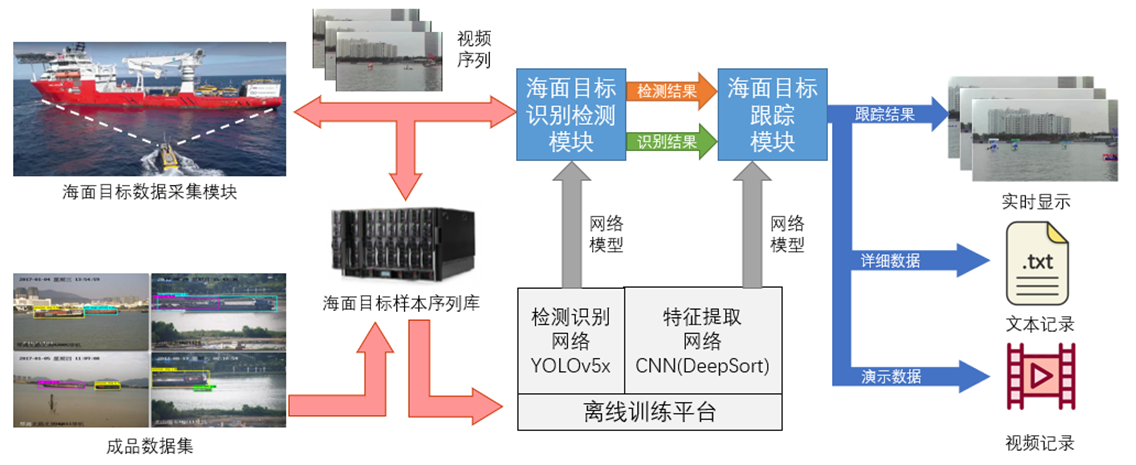
图1 可见光海面目标检测跟踪系统工作流程图
可见光海面目标检测跟踪系统工作流程如图1所示,系统各模块的功能如下:
1)海面目标样本序列库由无人艇在各个场景下采集回传的视频序列、参数和模型共同构建。在整套系统的使用过程中,随着无人艇回传新的目标序列,序列库也会不断的丰富自身;
2)海面目标检测的离线训练平台是在yolov5检测器框架下,对海面目标样本序列库中目标进行识别训练,借此构建可见光环境下的海面目标特征知识库,用于进行舰船目标的识别和分类;
3)海面目标数据采集模块用于在可见光环境下,使用无人艇对感兴趣的海面目标进行实时拍摄、并回传高分辨率的目标视频序列;
4)海面目标检测识别模块是基于无人艇回传的海面目标序列,尝试从图像中检测感兴趣的一类或数类目标,并选取检测时得分最高的类作为识别结果,;
5)海面目标跟踪模块在检测到存在海面目标后,开展后续的目标跟踪工作,将检测模块输出的目标框送入多目标跟踪器,处理后输出最终的结果。
本项目综合考虑了可见光海面目标的特点及无人艇采集数据时所面临的干扰,设计的海面目标在线识别平台架构如下:为保证检测精度,选取了yolov5作为海面目标检测器和分类器;随后将检测结果送入多目标跟踪器进行跟踪,这里我们选择deepsort算法作为我们的多目标跟踪器。
海面目标识别检测模块:
海面目标识别是整个系统中的第一个环节,也是最为基础的环节。作为后续识别、跟踪两个环节的基础,也是整个系统中要求最高的。由于整套系统是为侦查、监视等任务场景所设计,如果不能及时捕捉视野内的目标变化、错漏关键目标,后续的各项功能就会完全失效,极有可能导致严重的后果。在保证海面目标检测模块准确、稳定运行的同时,处理速度则是另一项关键指标。为了保证系统实时运行,全部流程的处理速度不能低于无人艇回传视频的帧率,再排除掉后续两个环节的耗时,对检测环节的速度提出了不小的挑战。
综合考虑上述问题,本项目采用YOLOv5算法作为可见光海面目标检测算法。
2016年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实时运行。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once(也就是我们常说的YOLO的全称),并将该成果发表在了CVPR 2016上,从而引起了广泛地关注。YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
时至今日,YOLO算法已经更新到了第五代。YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升,但是依然只需要一个神经网络就可以输出边界框。YOLOv5算法提供给了4个开源的处理网路,分别为:YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。这四种网络的体量依次增大,效果也随之变好,同时训练成本也逐级递增。本次研究中,经过反复试验,我们选择了体量最大,效果最好的YOLOv5x。
YOLOv5整体架构可以大致分为4个通用的模块,具体包括:输入端、基准网络、Neck网络与Head输出端。具体架构如图2所示:
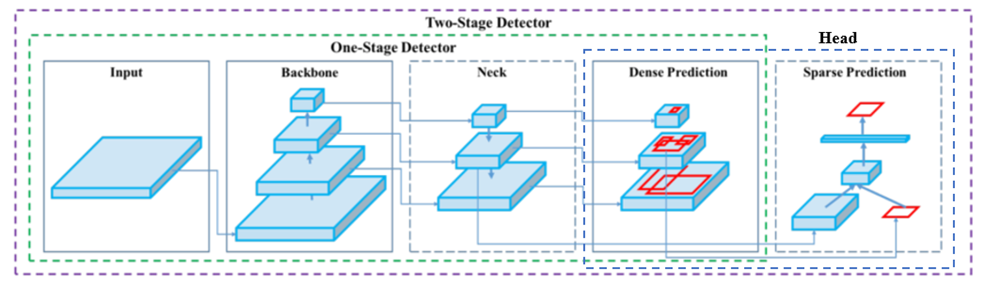
图2 YOLOv5总体架构
1)输入端
输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
2)基准网络
基准网络通常是一些性能优异的分类器网络,该模块用来提取一些通用的特征表示。YOLOv5使用了Focus结构作为基准网络,并引入CSPDarknet53结构,使网络的稳定性和准确性有了较大提升。
3) Neck网络
目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,这部分位于基准网络和头网络中间位置的网络被称为Neck网络。Neck网络可以进一步提升特征的多样性及鲁棒性。在YOLOv5中,Neck网络用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
4) Head输出端
Head用来完成目标检测结果的输出。输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。在损失函数方面,YOLOv5的损失函数由三部分组成,即:
 (1)
(1)
其中 是分类损失,采用BCE loss进行计算,且只计算正样本的分类损失;
是分类损失,采用BCE loss进行计算,且只计算正样本的分类损失; 是obj损失,采用的依然是BCE loss,这里的obj指的是网络预测的目标边界框与GT Box的CIoU,同时这里计算的是所有样本的obj损失;
是obj损失,采用的依然是BCE loss,这里的obj指的是网络预测的目标边界框与GT Box的CIoU,同时这里计算的是所有样本的obj损失; 是定位损失,采用的是CIoU loss,且只计算正样本的定位损失。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。两个分支的结果相融合,输出检测的最终结果(边界框)和分类结果(类标签)。
是定位损失,采用的是CIoU loss,且只计算正样本的定位损失。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。两个分支的结果相融合,输出检测的最终结果(边界框)和分类结果(类标签)。
海面目标跟踪模块:
对于完成检测、识别,并被判断为有必要进行进一步调查的海面目标,我们需要按照需求,监视并记录其后续动向。由于重要目标通常不止一个,因此我们添加了海面目标跟踪模块,实现舰船、漂浮物等常见海面目标的多目标跟踪功能。在这一阶段,我们采用了多目标跟踪(Multi-Object Tracking)中常用到的一种算法DeepSort,前身是Sort算法, 全称是Simple Online and Realtime Tracking。Sort最大特点是基于CNN的目标检测方法,并利用卡尔曼滤波算法+匈牙利算法,极大提高了多目标跟踪的速度,同时提高了目标识别的准确率。DeepSort相比于传统Sort算法中最大的特点是加入外观信息,借用了ReID领域模型来提取特征,减少了目标ID转换的次数。DeepSort算法在保证了稳定性的同时也保证了系统的实施运行速度,因此我们选择其作为我们的多目标跟踪器。Deep Sort算法的流程如图3所示。

图3 Deepsort算法流程
对于多目标跟踪问题, Deep Sort算法按照以下五个步骤进行处理:
步骤1:给定视频原始帧
步骤2:使用目标检测器在原始帧中对感兴趣的目标进行检测,获取目标检测框。
步骤3:对所有目标框中对应的目标分割,并进行特征提取(包括表观特征或者运动特征)。
步骤4:进行相似度计算,计算前后两帧目标特征之间的匹配程度。对于一个充分训练过的特征提取网络,同一个目标在两帧之间的特征距离要尽可能小,不同目标的特征距离则应当足够大,以便后续关联。
步骤5:数据关联,为每个对象分配目标的ID。
以上就是五个核心步骤,其中检测和关联的部分是算法的核心。检测的性能决定了整个算法的召回率,仅仅换一个更好的检测器,就可以将目标跟踪表现提升18.9%。这里我们将2.2中的检测结果直接导入,并采用CNN网络进行特征提取。而关联部分则决定了DeepSort算法的稳定性。
成果展示
(1) 系统程序界面:

图4 系统界面
系统界面如图4所示。界面主要分为三个区域:(1)参数设置区域;(2)交互显示区域;(3)运行可视化区域。参数设置区域位于界面左上角,用户可以在此处对待处理文件路径和系统参数进行设置。交互显示区域位于界面右上角,文本框内将会显示系统运行的各种信息,同时包含了设置文件路径、更新参数和系统启动的按钮。运行可视化区域位于界面下方,分为检测/识别可视化窗口(左下)和跟踪可视化窗口(右下)。检测/识别可视化窗口中将会实时显示YOLOv5x的检测结果,以目标框的形式呈现,识别出的类别标签则会标注在对应目标框上方。跟踪可视化窗口中将会实时显示跟踪结果,同样以目标框的形式呈现,目标框上方会同时标注出目标类别和其对应的轨迹号,例如某一目标类别号为1,轨迹号为25,则跟踪可视化窗口中会将其标注为“C1-T25”。
(2) 运行结果——检测:
(3) 检测/跟踪结果实时显示界面:
2. 视频SAR弱小目标检测预跟踪系统
项目背景
合成孔径雷达(Synthetic Aperture Radar, SAR)基于微波成像原理,相比于传统的光学成像具有全天时、全天候、穿透力强等优势,是军事领域中勘测地形和监视跟踪地面目标的重要设备。视频合成孔径雷达(Video Synthetic Aperture Radar, Video SAR)是基于SAR原理发展起来的一种新体制雷达,能够持续对感兴趣区域进行动态监测,输出多帧、连续、高精度成像。相比于传统SAR成像,视频SAR将成像结果以视频的形式给出,扩展信息获取的时间维度,动静结合,多维度特征地、直观地显示目标的位置、运动速度和运动方向等参数信息,为战场环境下的目标快速识别、威胁判断提供新的可靠支撑。目前基于视频SAR的动目标跟踪方法存在的技术瓶颈之一就是复杂动态背景强杂波噪声条件下时变数目多弱小机动目标跟踪问题,该技术瓶颈后还存在很多亟待解决的难点问题。
实施方案
研究内容1:基于相关滤波技术的单目标实时跟踪算法AD-PDA-BACF
由于复杂场景中存在的相似杂波噪声干扰,背景感知相关滤波器(BACF)的相关响应输出图中包含多个局部峰值(称作响应图多峰),其中最大输出响应位置可能偏离真实目标位置,则目标估计不准确。对BACF算法而言,它会在目标周围抽取大量正负样本训练分类器,然而不准确的跟踪结果将会导致抽样模糊,进而引发正负样本标记误差,这些误差在分类器学习阶段逐渐累积,最终会导致跟踪漂移。
为了解决响应图多峰问题,我们基于多峰量测提出一种外观-距离信息辅助概率数据关联(Appearance-Distance Information-assisted PDA,AD-PDA)算法估计目标状态。在此基础上,为了实现视频SAR阴影目标实时跟踪,我们联合AD-PDA算法和BACF算法提出了AD-PDA-BACF算法,算法跟踪流程如图5所示,其主要包含位置初始化模块、特征提取模块以及AD-PDA-BACF跟踪模块三部分组成。下面将对每个模块的内容做简要描述:
(1)位置初始化模块:根据目标框在初始帧的可靠位置和特征信息,初始化BACF滤波器和目标模板模型。
(2)特征提取模块:提取目标强度特征和FHOG特征并在通道维度上进行级联,获得目标多通道融合特征。
(3)AD-PDA-BACF跟踪模块:首先基于BACF算法的相关响应输出选择多个量测作为关联门内量测;其次,根据目标运动和量测模型分别预测目标状态和量测;再次,计算混合关联概率,并采用AD-PDA算法估计目标状态;最后,基于当前时刻目标的估计状态,提取目标特征,并在线更新目标特征模板。
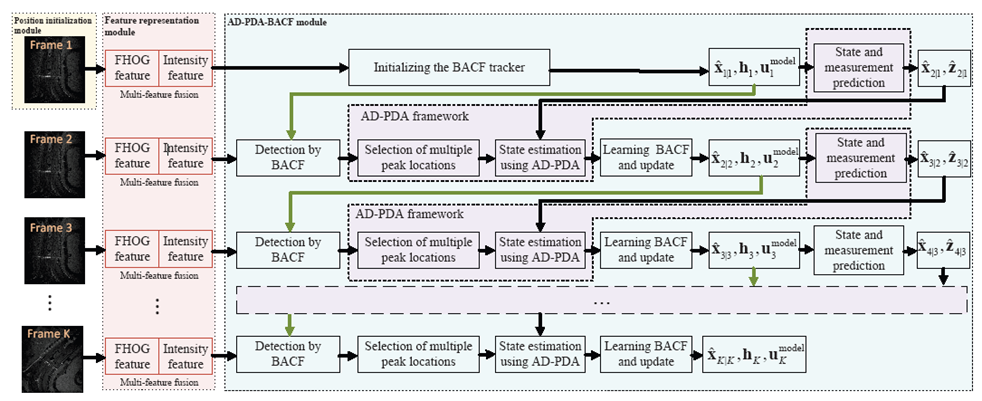
图5 AD-PDA-BACF算法流程图
研究内容2:基于检测前跟踪技术的多目标联合检测与跟踪算法ES-TBD和RP-TBD
为了有效解决机动目标跟踪问题,我们提出一种新颖的基于胀缩搜索策略的DP-TBD(Expanding and Shrinking strategy-based DP-TBD,ES-TBD)算法。首先,ES-TBD基于目标上一时刻的状态,采用独立粒子滤波器,根据机动目标运动模型,对目标的可能转移状态进行大范围预搜索,生成膨胀预测子区域;然后,基于视频SAR量测模型,根据贝叶斯公式计算各预搜索路径的后验概率,更新独立粒子滤波器中预测粒子权重,并进行粒子重采样,有效减少相异粒子数目,收缩膨胀预测子区域,获得目标收缩预测状态;最后,目标状态更新。基于目标的收缩转移状态,进行幅度值函数递推积累,经过K帧积累后,通过门限判决和航迹回溯,最终获得目标个数和状态估计。
图6显示传统DP-TBD算法和ES-TBD算法中的目标状态转移情况对比。目标在k -1时刻的初始状态为xk -1=[4,3,6,3]',候选转移状态数量Ns =4。蓝色星标表示目标的真实位置。图(a)显示传统DP-TBD算法目标状态转移情况。彩色实线框(红、绿、蓝、黄、紫色)表示目标可能的转移状态。可以看到,在k+1时刻,目标可能的转移状态不包含目标的真实状态。
在ES-TBD算法中,采用膨胀收缩策略确定有效候选状态,图(b)显示了提出的ES-TBD算法目标状态转移情况。彩色虚线框(紫、蓝色)表示膨胀预测子区域,而红色实线框表示收缩预测子区域。与传统的DP-TBD算法相比,ES-TBD算法的搜索范围扩大了,因此,ES-TBD算法对机动目标检测和跟踪具有更强的稳健性。ES-TBD算法通过重采样机制从膨胀预测子区域中选择若干后验概率大的目标可能状态,形成收缩预测子区域,从而搜索到真实目标,同时保留了目标的最优路径。
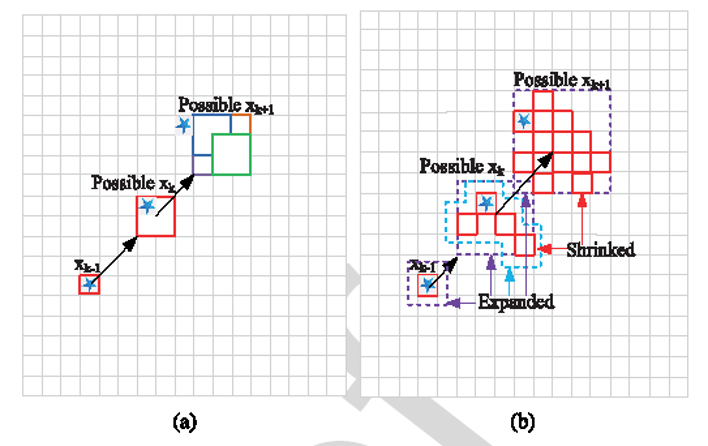
图6 传统DP-TBD算法(a)和ES-TBD算法(b)中的目标状态转移情况对比
为了检测和跟踪数目随时间变化的多个机动目标,我们研究发展了基于区域划分的DP-TBD(Region-Partitioning-based DP-TBD,RP-TBD)算法。RP-TBD算法流程图如图7所示。首先,对量测序列进行批次划分,采用滑窗法将图像序列分为若干量测批次,并对每个量测批次中的图像帧序列进行划分,确定公共量测帧序列和特有量测帧序列;其次,对图像子区域划分,确定量测批次中的每一帧图像(公共量测帧或特有量测帧)中的已知子区域和新子区域,最终获得量测批次中的已知子区域序列和新子区域序列;再次,利用已知子区域序列中的量测,采用附加值函数的独立PF算法跟踪已知目标和检测已消失目标;利用新子区域序列中的量测,采用ES-TBD算法检测和跟踪新出现的目标;最后,获得多目标跟踪航迹。

图7 RP-TBD算法流程图
成果展示
(1) 单目标跟踪结果演示:
视频中展示了AD-PDA-BACF跟踪美国桑迪亚实验室发布的视频SAR-Victr数据集中目标的结果。该数据集共有398帧图片,在视频帧中左上角用蓝色字体标示图像帧序号。视频中用蓝色方框标示真实目标位置,用红色方框标示AD-PDA-BACF算法估计的目标位置。
(2) 多目标跟踪结果演示:
视频中展示了RP-TBD算法跟踪美国桑迪亚实验室发布的视频SAR-Highway数据集中多目标的结果。跟踪可视化窗口中将会实时显示跟踪结果,同样以彩色目标框的形式呈现不同目标估计位置,目标框右下方会同时标注出目标的序号,如目标1被标记为T1,其在各帧的估计位置均采用蓝色方框标示。
3. 基于前馈神经网络的大规模点云三维全息快速计算方法
3.1 研究背景
三维全息显示是一种极具潜力的显示技术,它能重建三维(3D)物体的波前信息,并为人眼提供三维感知。全息图是实现全息三维显示的关键,传统全息术采用相干光干涉制作全息图,相对苛刻的实验条件使得制作全息图并非易事。1965年德国光学专家罗曼(Lohmann A W)使用计算机和绘图仪生成了世界上第一个计算全息图。计算全息图不仅可以全面地记录光波的振幅和相位,而且能够记录综合复杂的,或者世间不存在物体的全息图,因而具有独特的优点和极大的灵活性。
随着计算机技术和相位调制技术的不断进步,数字全息三维显示受到广泛关注,计算全息术也进入了快速发展时期。根据三维模型数据结构,计算全息方法主要分为点源法、面源法及体素法。其中点源法在全息图计算中具有简单易用、计算效率高、适用性广泛和理论基础强等优势,使其成为全息学研究和实践中常用的方法之一。然而,针对于大规模点云模型(百万级物点以上),利用点源法生成计算全息图十分耗时。尤其当计算全息图分辨率达2K,制作一张百万级规模点云的计算全息图需要处理至少2Mx1012次浮点运算(其中M为单次计算数),这限制了计算全息三维实时显示的发展。
为了加速点源法计算全息图,查表法(LUT)、波前记录平面法(WRP)、深度图法、全息体式图法及硬件加速法等算法被提出,以上方法可以组合使用,来实现计算全息加速优化。根据研究数据表明,与原生算法相比,增加硬件加速模式后,并行化使计算效率极大提升,计算用时显著下降。此外由于商用GPU算力提升,硬件加速方法已成为标准化加速方案。然而,由于计算全息的复杂性,基于点源算法框架的并行化并不能充分发挥硬件的效能。因此,如何提出一种能够更加高效计算全息图的并行化方法成为研究焦点。
3.2 大规模点云全息图生成网络
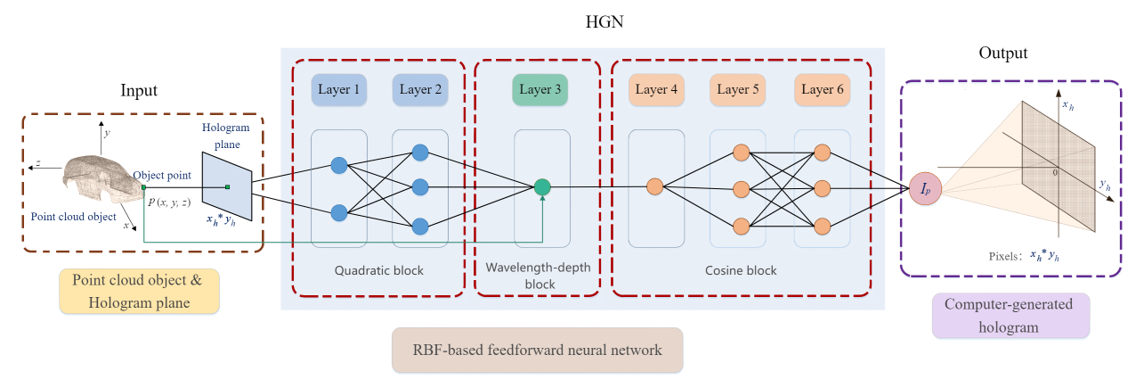
图1 基于HGN的点云全息图生成系统
立足于大规模点云模型快速计算全息图并行化问题,我们提出点云菲涅耳衍射模型的前馈神经网络表达范式,构建了基于全息图生成网络的点云全息图生成系统,如图1所示。在该系统中,我们综合分析了三维点云数据、神经网络结构与点源法原理,设计了张量化数据流处理管线,构建了点云输入与全息子图输出的端到端全并行框架,数据流处理过程如图2所示。
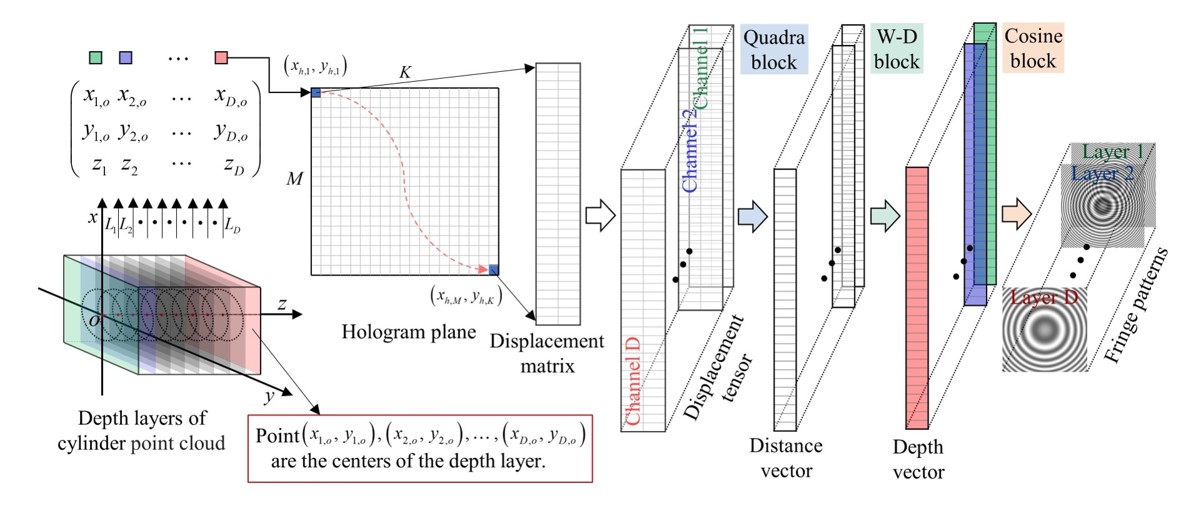
图2 张量化数据流处理管线
在点云全息图生成系统中,我们基于菲涅耳衍射模型构建训练HGN所需的结构化数据,极大的提高了数据集构建的灵活性。此外,通过研究三维点云模型菲涅耳衍射的编码规则,将光波场的相空间映射到单一周期,这使得小规模网络即能够学习衍射模型,进而提高HGN前馈传播效率。对于大规模点云模型,我们基于采样定理设计了点云分层算法,构建了基于深度层的点云表现形式,在同一深度层中的物点被视为一个计算单元,计算全息图合成流程如图3所示。
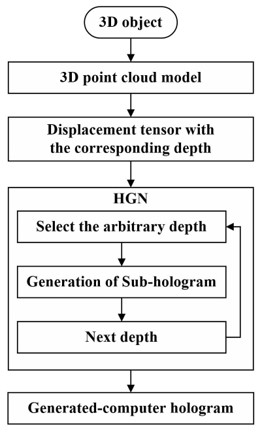
图3 计算全息图合成流程
3.3 光学再现系统

3.4 实验结果与分析
3.4.1 state-of-art算法计算全息时间对比


图4 state-of-art算法计算全息图时间对比
3.4.2 三维点云模型数值与光学再现显示效果
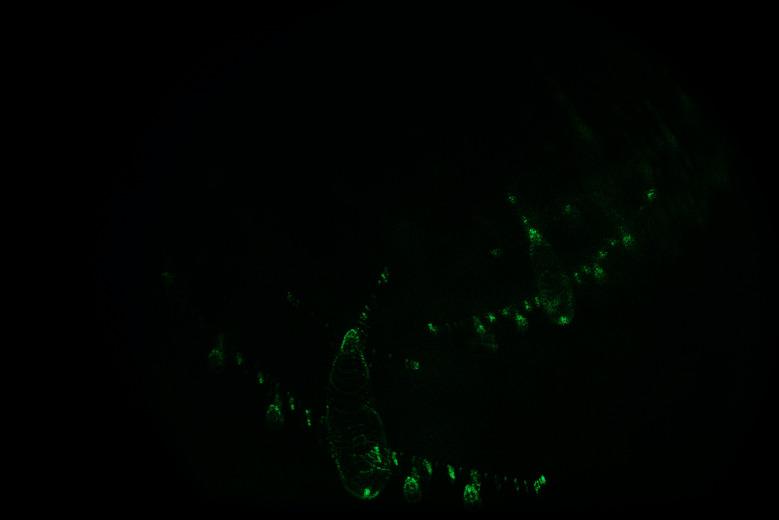
(1)near

(2)far
图5 计算全息图在不同重建距离时光学再现结果

图6 大规模点云模型计算全息图的光学再现

图7 89457个物点Stanford Bunny4k分辨率计算图数值再现

图8 小规模点云4k分辨率计算全息图数值再现
4. 基于神经图元的三维光场稠密视点编码算法
4.1 研究背景
在使用视差图像生成投影仪图像阵列(PIA)时,巨大的渲染时间是一个挑战。基于神经辐射场(NeRF),本研究提出了一种新颖的直接渲染PIA子图像的方法,以加速三维光场编码。该方法独特地结合了3D光场编码和最新的即时神经图形元(NGP)技术,展示了如何快速获得高质量的PIA。NGP被用来加速NeRF的训练和渲染,并通过利用多分辨率哈希网格容器来提高渲染视差图像的质量。在传统的光场编码方法中,光线被视为连接显示系统和隐式辐射场的关键对象。通过将实际显示系统的光场作为输入到NGP网络,所提出的方法可以直接获得单个投影仪中显示的子PIA。对于分辨率为720×1280的投影仪,在单NVIDIA GXT 3090算力平台,sub-PIA的渲染时间仅为25毫秒。
4.2 基于Instant-NGP的稀疏光场编码
4.2.1 总体框架

图1 基于理想摄像机的像素级光场渲染框架
如图1所示,基于即时NGP的NeRF仍然包含两个阶段,即隐式3D光场的学习和新视角图像的渲染。与传统的NeRF不同,输入至即时NGP的网络输入是一个预处理向量,该向量由“物体点”的光线编码。使用稀疏图像作为源数据,用于构建可编码的训练样本,训练后的网络随后可以作为光场的隐式表示,能够合成之前不存在的新视角图像。根据3D光场编码的原理,仅使用视差图像中的目标像素列来合成子PIA。因此,我们开发了一个特定的渲染管线,该管线仅渲染用于编码的光,以绘制投影仪的“元素图像”。
4.2.2 基于光线方程的投影仪阵列图像渲染
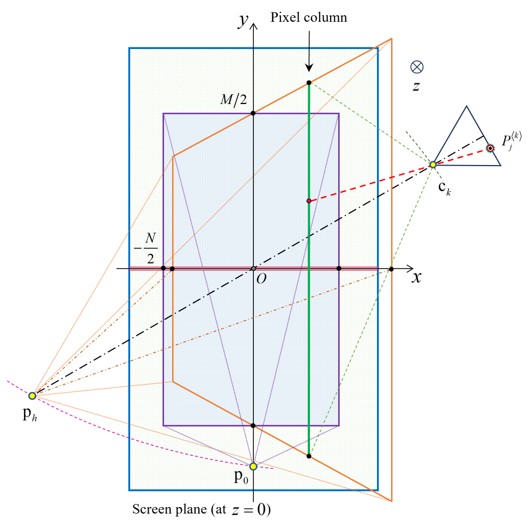
图2 基于理想摄像机的像素级光场渲染
渲染过程中生成的像素列被堆叠形成子PIA,如图2所示。这一步骤至关重要,确保像素列能够按照预定顺序正确对齐和定位,为投影数据的准备提供了保障。通常情况下,投影仪阵列被安装在以画布中心为中心的同心弧形支架上。然而,实际安装的投影仪往往与光轴方向的理想位置存在偏差。这些位置偏差对应于渲染管线中的摄像机参数。一旦投影仪的位置发生误差,就需要在渲染管线中重新计算摄像机参数。为了解决这个问题,我们在渲染管线中增加了一个位姿误差矫正功能,如图3所示,以确保渲染结果的准确性。
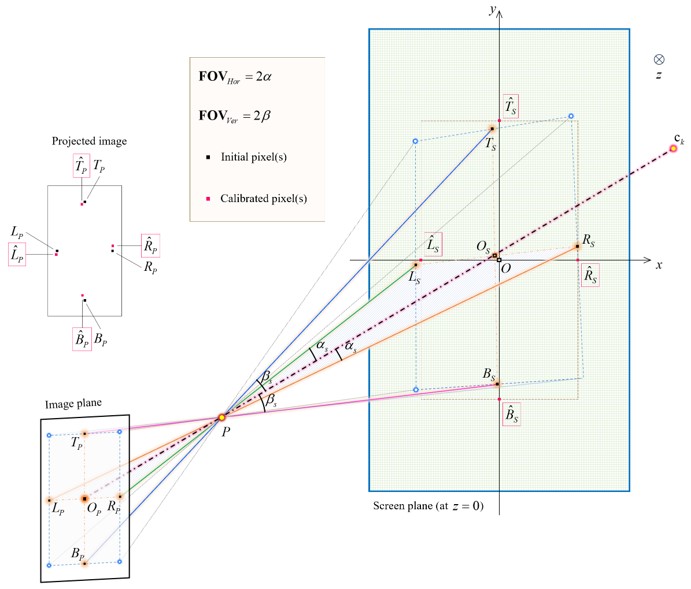
图3 计算采样相机的相对位置参数
4.2.3 投影图像阵列合成
图4 投影阵列子图合成
图4展示了生成PIA的流程图。在训练过程中涉及的摄像机内部参数在所有采样摄像机中保持一致。然后,摄像机的外部参数由投影仪发出的光线确定。在神经辐射场(NeRF)中,光线的生成本质上依赖于多个摄像机参数,包括摄像机的位置、方向和内在属性,如焦距。在需要渲染指定像素列的情况下,获取这些列的索引就变得必要,这些索引是基于光线来确定的。当关注点缩小到渲染单一列像素时,遍历操作将严格限制在指定列的像素点内。
4.3 实验平台

图5 三维显示平台及系统
4.4 实验结果
4.4.1 不同视点的显示效果(相机拍摄)
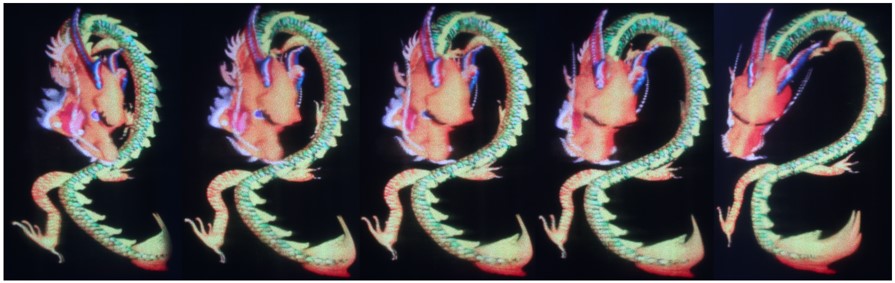
图6 基于所提出算法的三维显示效果
4.3.2 真实场景的显示效果
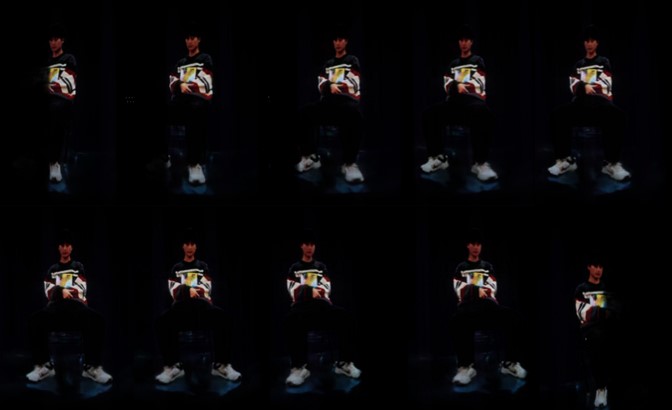
图7 真实场景中人物三维显示效果

图8 真实场景中外景三维显示效果



