Relational Grasp Dataset
Background
Robotic grasping is a fundamental problem in robotics. It plays a basic role in nearly all robotic manipulation tasks. Particularly, visual perception is important for robotic grasping, since it can provide rich observations about the surroundings. Surprisingly, with the rapid development of deep learning techniques, robotic grasping has achieved impressive progress in recent years. A bunch of excellent researches for robust robotic grasp generation appear. However, grasping in realistic scenarios is usually target driven. In most cases, it is not a simply segregated task but should involve comprehensive and high-level visual perception.
Despite the impressive progress achieved in robust grasp detection, robots are not skilled in sophisticated grasping tasks (e.g. search and grasp a specific object in clutter). Such tasks involve not only grasping, but comprehensive perception of the visual world (e.g. the relationship between objects). Recently, the advanced deep learning techniques provide a promising way for understanding the high-level visual concepts. It encourages robotic researchers to explore solutions for such hard and complicated fields. However, deep learning usually means data-hungry. The lack of data severely limits the performance of deep-learning-based algorithms. Therefore, we propose a novel, large-scale, and automatically-generated dataset for safe and object-specific robotic grasping in clutter.
Dataset Introduction
RElational GRAsp Dataset (REGRAD) is a new dataset used to model the relationships among objects and grasps. It aims to build a new and robust benchmark for object-specific grasping in dense clutter. We collect the annotations of object poses, segmentations, grasps, and relationships in each image for comprehensive perception of grasping. Our dataset is collected in both forms of 2D images and 3D point clouds. Our dataset is collected in both forms of 2D images and 3D point clouds. Moreover, since all the data are generated automatically, users are free to import their own object models for the generation of as many data as they want.

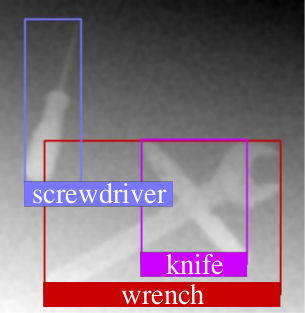
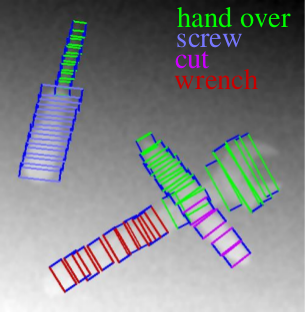
Fig. 1: Some examples of REGRAD. The images are taken from 9 different views and the background is randomly generated
Dataset Features
To support comprehensive perception for realistic grasping and train large deep models, our dataset possesses the following features:
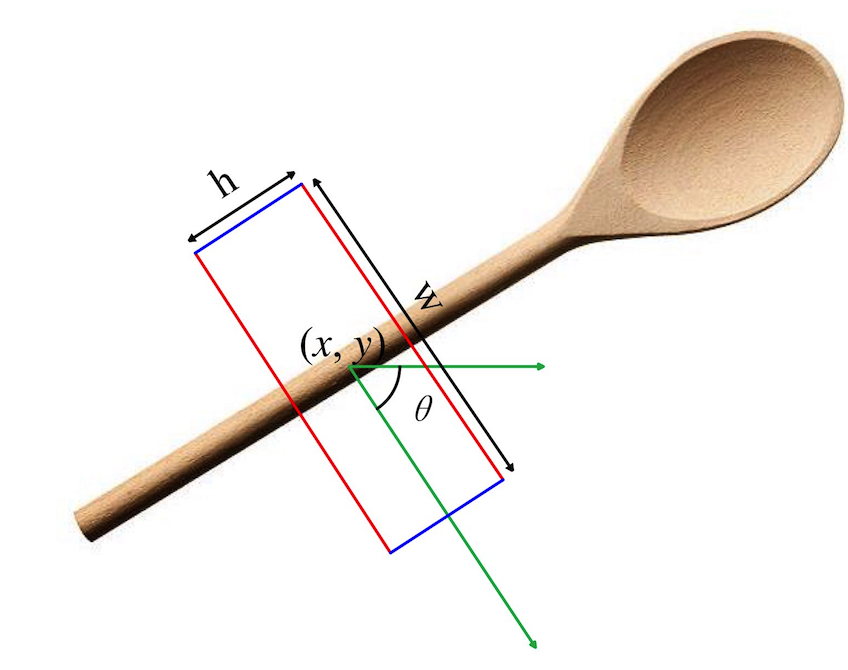
- Data are rich. The dataset contains 2D color and depth images as well as 3D point clouds. The labels include: 6D pose of each object; Bounding boxes and segmentations on 2D images; Point cloud segmentations; Manipulation Relationship Graph indicating the grasping order; Collision-free and stable 6D grasps of each object; Rectangular 2D grasps.
- Multiple views. We record the observations in 9 different views for each scene of our dataset, aiming to call for researches on robust goal-oriented object searching and grasping with multi-view visual fusion.
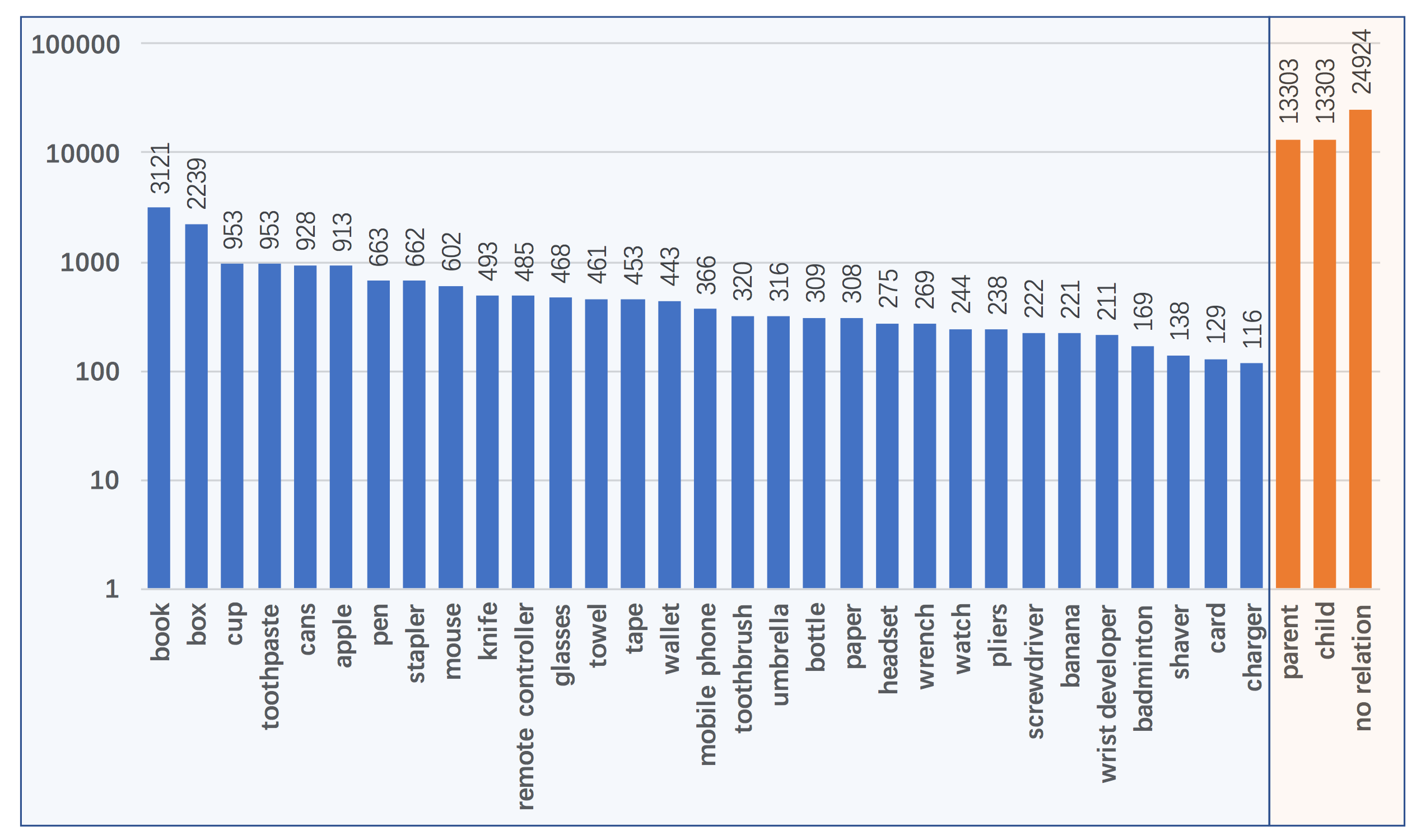
- More objects and categories. Our dataset is build upon the well-known 3D model dataset ShapeNet. Specifically, there are totally 55 categories including 50K different object models.
- More scalable. Compared to previous datasets like VMRD, it is much easier to expand REGRAD for more training data since all labels are generated automatically. The only thing left to do is to find more suitable 3D object models. We also provide open source codes for dataset generation.
- A systematic way for scene generation without the intervention of humans. Previous relationship datasets are generated manually, which will introduce human bias. In this paper, all the scenes are generated automatically according to a carefully designed procedure to avoid such bias.
Dataset Download
Downloading of our dataset is free and open. Please cite the paper: “REGRAD: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter”
The subset of dataset can be downloaded at this link:
If you want to obtain the full dataset, please email: http://reload7@stu.xjtu.edu.cn